|
Content Syndication wird zum Megatrend im Internet - Teil 2:
(Fortsetzung von Teil 1)
XML-Standards sind die Säulen des Content Syndication
XML ermöglicht frei definierbare Markup-Sätze, quasi Dialekte von XML. Für den automatisierten Austausch von Webinhalten zwischen einem Syndicator und einem Subscriber gibt mehrere Standards wie ICE, NewsML, NITF oder PRISM.
XML macht Content datenbankfähig
Der größte Vorteil von XML besteht darin, dass durch die Dokument-Strukturierung ein feinkörniger Zugriff auf die Informationen in gleicher Weise möglich ist, wie der Feld- und Datensatz-Zugriff bei relationalen Datenbanken.
Jedes Struktur-Element im Dokument - eigentlich innerhalb der Sammlung aller Dokumente - kann gemeinsam genutzt, wiederverwendet, wiedergefunden und verwaltet werden. Diese Elemente sind gewissermaßen der Schlüssel zu allen wichtigen Informationen, die in einem Dokument verborgen sind.
Seine Vorzüge beweist XML aber nicht nur bei der Gestaltung und ausgabeneutralen Speicherung von Dokumenten und Webinhalten, sondern auch beim Dokumenten-Management: Zeit- und speicherzehrende Mehrfachablagen von immer wiederkehrenden Textelementen (typisch für technische Dokumentationen) lassen sich so vermeiden. Als entscheidende Erweiterung gegenüber HTML bietet XML eine objektorientierte Verwaltung für beliebige Datentiefen.
ICE automatisiert die Syndizierung
Ein Konsortium von Publishern und Softwareunternehmen unter der Federführung der IDEAlliance, einer herstellerunabhängigen Organisation der Graphic Communications Association's (GCA) <www.idealliance.org,>, schlug 1988 einen XML-Standard für den Information Content and Exchange (ICE) vor, mit dem das Syndizieren im Web vereinfacht werden sollte. Weitere Mitglieder dieses ICE-Kconsortiums sind u.a. Active Data Exchange, Adobe Systems Corp., Fresher Information Systems, Herrick-Douglas, Kinecta Corporation, Microsoft Corporation, National Semiconductor, Plumtree Software, Seagate, Sotheby's, Sun Microsystems, Tribune Media Services, Vignette Corporation, Wavo Corporation und What U Want, Inc.. Heute zählen über 70 Unternehmen dazu. Im Juni 2000 wurde die Version 1.1 freigegeben <www.icestandard.org>.
Das ICE-Protokoll ermöglicht es, Daten unterschiedlichster Herkunft über das Internet von einem System in ein anderes zu transportieren. Dabei kann die Art und die Struktur der Daten von den entsprechenden Kommunikationspartnern außerhalb des ICE-Protokolls spezifiziert werden.
Vollautomatischer Datenaustausch
Ziel der ICE-Architektur ist der vollautomatische Datenaustausch ohne manuellen Eingriff und ohne Kenntnisse über die Verzeichnisstruktur der Quelle. Die ICE-gemäß ausgezeichneten Inhalte können auf der Empfängersite ausgewertet und unter neuer Flagge weiter zum Verkauf angeboten werden. Mit ICE können Syndikationsnetzwerke, Web-Superstores und Online-Vetriebskanäle im B2B-Bereich sehr einfach realisiert werden.
ICE-basierte Produkte werden von Firmen wie Arcadia, Intershop, Kinecta, Macromedia, Quark, Vignette und Xenosys angeboten und haben sich bereits bestens bewährt. Der ICE Syndication Server arbeitet mit den Content Management Systemen zusammen, aus denen er Content herauszieht und neuen Content einlädt. Dank ICE gibt es eine Standard-Schnittstelle zwischen Syndikatoren und ihren Partnern. Bisher mussten hier mit hohem Arbeitsaufwand jeweils individuelle Abläufe installiert werden, nun wird Syndikation ein problemlos skalierbarer Prozess, ohne großen Kostenaufwand für die Distributionsinfrastruktur.
Distribution und Subskription
Ein Syndication Server besteht in der Regel aus zwei Komponenten. Mit dem Distributionsmanager spezifiziert der Syndikator die verfügbaren Content-Angebote auf seinem Server. Der Subskriptionsmanager ermöglicht den Partnern die Sichtung dieses Angebots. Auf der Subscriberseite sorgt der Syndikationsagent dann für die ICE-gemäße Übertragung: er kontaktiert den Syndikator, ruft den Content ab, packt ihn aus und stellt in seinem CM-System zur Verfügung
Das ICE-Protokoll ist kompatibel zum Open Profiling Standard (OPS), der von Netscape, Firefly und Verisign favorisiert wird. Die Spezifikation definiert Regeln für die automatische Verteilung von Content (einschließlich Werbung) zwischen verschiedenen Websites und die Verwendung dieses Contents auf den einzelnen Sites. ICE-basierte Programme managen und automatisieren die Syndikationsbeziehungen, den Datentransfer und die Ergebnisanalyse. ICE setzt dabei auf branchenspezifische Glossarien auf, ist aber für sich zunächst völlig anwendungsneutral: von einfachem ASCII-Text über HTML bis zu XML oder Rich Media kann alles als Content verteilt werden. Nur die bidirektionale Meta-Kommunikation zwischen den Servern, also die Verständigung über die Abläufe, ist an XML gebunden.
Die Grundlagen des ICE-Protokolls
Das ICE-Protokoll für den Contentaustausch zwischen verschiedenen Servern setzt auf den XML Document Type Definitions (DTDs) auf. Mit diesen anwendungs- und branchenspezifischen DTDs, deren Entwicklung nicht ganz trivial ist, steht und fällt das Konzept der automatisierten Content-Syndizierung. Eine DTD ist vergleichbar mit einem Thesaurus semantischer Kategorien und muss für jede Anwendung so umfassend wie möglich sein: eine DTD für die Luftfahrttechnik hat aber nur geringe Schnittstellen mit einer DTD für das Gesundheitswesen. Organisationen wie Rosetta.net <www.rosetta.net>, Ontology.org <www.ontology.org>, und CommerceNet <www.commercenet.com> bieten hier bereits branchenspezifische Lösungen für den Austausch von Daten und Dokumenten an.
Im ICE-Modell ist der Syndicator der Content-Lieferant und der Subscriber der Abnehmer, der seinerseits den Endverbraucher beliefert. Sowohl der Subscriber als auch der Syndicator müssen ICE-basierte Programme einsetzen, entweder integriert in ihrem Content Management System oder als eigenständiges Programm. Der Informationsfluss erfolgt dabei bidirektional: so kann der Syndicator etwa Informationen über das Nutzerverhalten seitens des Subscribers erhalten.
Request und Response
Charakteristisch für das ICE-Protokoll ist das Anfrage-Antwort-Modell. Jeder Request hat eine eindeutige Kennung und erfordert zwingend einen Response. Der Subskriptionsvorgang beginnt mit der Anforderung des Katalogs durch den Subscriber.
Das ICE-Protokoll kennt vier Operationsgruppen:
1. Subskriptions-Management
2. Datenübermittlung
3. Ereignisprotokollierung
4. Verschiedene Operationen
Das Subskription-Management deckt alle Schritte des Subskriptionsvorgangs ab: Beginn, Häufigkeit und Ende, Liefermodus (Push oder Pull) und Zustelladresse (URL). ICE sieht auch die Übertragng von Metadaten wie Nutzungsbeschränkungen, Dringlichkeit, Copyright, Autorennennung etc.. Bei Streaming Content (Video, Audio) können die Tage und Zeiten exakt vorgegeben werden, zu denen der Subscriber Zugriff auf den Stream hat.
Content fließt paketweise
Die Datenübermittlung ist der Kern des ICE-Protokolls: es sieht eine Abfolge von Datenpaketen vor, die den Content entweder komplett oder inkremental auffrischen. Der Content kann unmittelbarer Teil des Streams sein oder über URLs referenziert werden. Kommt ein Paket beschädigt beim Subscriber an, kann automatisch ein Neuversand ausgelöst werden.
Die Ereignisprotokollierung ist für die Analyse von Fehlern unentbehrlich. Das ICE-Prokoll codiert im Server-Logfile alle Events durch dreistellige Zahlen und einen Fehlerstring. Eine automatische Benachrichtigung des Administrators bei Störungen ist ebenfalls möglich.
Die ICE-Spezifikation stellt eine XML-basierte Architektur bereit, mit der ganz neue Dienstleistungen im Finanzbereich, im Publishing oder bei Reiseangeboten möglich sind.
NewsML und NITF sind DTDs für die Publishingwelt
Der Einstieg in die komplexe ICE-Struktur fällt leichter, wenn man sich zunächst mit zwei Document Type Definitions (DTSs) befasst, die bei Nachrichtenagenturen wie dpa und diversen Tageszeitungen bereits etabliert sind: NewsML und NITF.
Sowohl NITF als auch NewsML können für sich allein oder i ergänzend gemeinsam eingesetzt werden, da NITF-Objekte in einer Multimedia-Anwendung von NewsML gemanaged werden können. NewsML ist also eine Erweiterung für Multimedia-Content.
NewsML ist XML für Multimedia
NewsML ist ein Format zum automatisierten Erzeugen Austauschen, Übertragen und Archivieren von Agenturmeldungen. Es ist medienneutral und eignet sich für einfachen Text ebenso wie für TV-Meldungen. NewsML liefert eine Struktur, mit der Nachrichten jedweder Art verknüpft werden können. Bilder, Texte, Grafiken, Videos und Audiofiles können als zentrales Element eines sogen. NewsItem oder als Sekundär- oder Tertiärelement definiert werden. So kann etwa eine TV-Meldung mit Hintergrundtext und weiteren Standbildern verbunden werden.
Das Revisionsmanagement, also die Kontrolle aller Versionen eines Beitrags, ist eine zentrale Funktion in NewsML. Eine Aktualisierungsfunktion sorgt dafür, das ältere Versionen einer Item-Komponente durch die jeweils aktuellste ersetzt werden. NewsML ermöglicht die Verknüpfung verschiedener NewsItems oder ganzer Gruppen von NewsItems, die in einem thematischen Bezug zueinander stehen (related news). So entstehen mit der Zeit ganze Themengeflechte im Netz.
Bei der Präsentation kann der Nutzer zwischen verschiedenen Formaten einer Komponente - HTML, RTF oder PDF wählen. Besonders bei Fotos ist das interessant, da mehrere Auflösungen und Dateiformate eines Bildes angeboten werden können. Für zukünftige Abrufgeräte der UMTS-Generation ist das unverzichtbar. NewsML kann auch den Ausschluß bestimmter Medienformate bei bestimmten Übertragungswegen vorsehen, damit nicht etwa ein HighRes-Videostream auf einem Handy landet..
Bezüglich des Layouts gibt NewsML keine Vorgaben, erlaubt aber die Beifügung von StyleSheets, die die strukturelle Information in Gestaltung umsetzen. Auch bei den Metadaten zur Beschreibung des Contents kann auf beliebige andere Standards wie etwa IPTC (dazu mehr unter NITF) zugegriffen werden.
News Industry Text Format macht der Zeitung Beine
Inhalt und Struktur eines Zeitungsartikels lassen sich mit dem News Industry Text Format NITF beschreiben: NITF ist eine XML-basierte Document Type Definition (DTD). Durch diese Anreicherung mit Metadaten sind Zeitungsartikel viel effektiver suchbar und nutzungsfreundlicher als HTML-Seiten. Entwickelt wurde das offene NITF vom International Press Telecommunications Council IPTC, einem unabhängigen internationalen Verband, dem die führenden Verleger und Nachrichtenagenturen angehören, sowie von der Newspaper Association of America.
Die ersten Schritte begannen schon 1990 auf der Basis von SGML; als 1998 XML verabschiedet wurde, hat man NITF XML-kompatibel gemacht Heute liegt NITF in der Version 2.5 vor und ist weltweit die am weitesten verbreitete XML-Verlagsanwendung. Da NITF auch in Deutschland bereits von der Deutschen Presseagentur dpa eingesetzt wird, wollen wir uns ausführlicher mit NITF beschäftigen.
Mit NITF können Publisher das Erscheinungsbild und die Interaktivität ihrer Dokumente an die Bandbreite und andere Eigenheiten des Ausgabesystems und die individuellen Ansprüche ihrer Abonnenten anpassen. So ist beispielsweise eine automatisierte Übertragung in HTML, WML (für funkgebundene Systeme), RTF (für den Druck) oder jedes andere Format möglich. Sehr viele Texteditoren und Layoutprogramme unterstützen oder bewahren zumindest die NITF-Tags.
Die Metadaten der NITF-Tags liefern eine Fülle von Informationen über einen Artikel. Um nur die wichtigsten zu nennen:
- Wer hat das Copyright, wer darf den Artikel veröffentlichen und womit befasst er sich?
- Welche Themen, Organisationen, Veranstaltungen und Ereignisse werden behandelt?
- Wann wurde er erstellt, veröffentlicht und überarbeitet?
- Wo wurde er geschrieben, wo ist der Ort der Handlung und wo darf er publiziert werden?
- Worin besteht sein Nachrichtenwert?
Details zu NITF findet man auf www.NITF.org.
Noch ein XML-Vokabular: PRISM
Damit es an Vielfalt nicht mangelt, wurde im Dezember 2000 die neue Version von PRISM (Publishing Requirements for Industry Standard Metadata) verabschiedet. Dieses standardisierte Metadatenvokabular soll den herstellerunabhängigen Content-Austausch zwischen verschiedenen digitalen Asset und Content Management Systemen im Online- und Printbereich gewährleisten. PRISM verknüpft dabei vorhandenen Standrds wie XML, RDF (Resource Description Framework, ein XML-basierter W3C-Standard zur Wissenrepräsentation im Web), NewsML sowie den Dublin Core: ein schon etwas älterer Metadatenstandard von 1995, der besonders im Bibliotheksbereich genutzt wird.
Die Abgrenzung und Unterscheidung der diversen Mtadatenstandards ist nicht ganz einfach: teilweise überlappen, teilweise ergänzen sie sich. In der PRISM-Spezifikation findet man dazu einige hilfreiche Erläuterungen.
Topic Maps: Die Alternative für unstrukturierten Content
Ein alternatives und sehr interessantes Verfahren zur Content-Syndizierung bietet der Topic Maps- Standard ISO/IEC 13250 (Januar 2000) an. Im Unterschied zu den vorgenannten Verfahren, bei denen die Information bereits strukturiert aufbereitet wird, können mit Topic Maps alle vorhandenen unstrukturierten Informationen navigier- und suchbar gemacht werden. Vergleichbar dem Inhaltsverzeichnis eines Buches wird ein Topic Map nachträglich als Navigationslayer über den Artikel gelegt. Hintergrundinformationen zu diesem Standard findet man auf /www.infoloom.com und auf www.oasis-open.org/cover/topicMaps.html.
Der auf XML basierte Standard beschreibt ein nach Inhalten strukturiertes Netzwerk von Metadatenbeschreibungen. Damit können Informationen über Informationen organisiert und assoziativ verbunden werden. Eingesetzt werden solche Lösungen vor allem für personalisierte Informationsprogramme und maßgeschneiderte Content Lösungen im Internet.
Pressetext AG setzt auf Topic Maps
Die Pressetext Austria AG wird diesen Standard ab 2001 für ihre Content Syndikation (www.newsfox.com) einsetzen. "Pressetext wird den Metadatenstandard Topic Maps einsetzen, um seine Informationsangebote für den Kunden maßgeschneidert strukturieren und punktgenau ausliefern zu können", erklärt der technische Direktor von pte, Markus Schranz. Ein Topic umfasst dabei für jede Information in der Datenbank eine Kurzbeschreibung und eine semantische Kategorisierung der Inhalte. Über frei konfigurierbare assoziative Verbindungen zwischen den Topics können für den Kunden maßgeschneiderte Selektionskriterien aufgesetzt werden. So z.B. können einem Handy-Portalbetreiber Nachrichten aus verschiedensten Informationskanälen zum Thema Handy, WAP und SMS geliefert werden.
Print to Web: Von QuarkXpress zu XML
Über XML-Autorenprogramme haben wir bereits im DD 07/2000 (w01) berichtet. Zwei kleine Tools seien hier noch erwähnt, mit deren Hilfe man Dateien aus dem beliebten Layoutprogramm QuarkXpress automatisch in eine XML-Struktur überführen kann. Einigen Syndikatoren wie etwa www.magazinecontent.com genügt diese layoutorientierte XML-Struktur vollauf.
XPress XML lässt sich am einfachsten als Reinkarnation des XPress Tag-Filters charakterisieren. XPress XML importiert und exportiert formatierten Text in und aus QuarkXPress genauso, wie das XPress Tag-Filter. Weil XPress bereits mit XML arbeitet, ist es viel einfacher zu bedienen. Die mit Xpress XML gewonnenen XML-Dateien können von jeder Standard-XML-Anwendung verarbeitet werden.
RoustaboutXT ist eine Xtension für QuarkXPress, die formatierten Text als XML exportiert. Dabei werden Absätze und Zeilenumbrüche ebenso bewahrt, wie die Stylesheet- und Formatierungsinformationen. Beide Tools können auf www.attd.com bestellt werden.
Eine komfortablere, aber auch teurere Lösung, um printorientierte Quark-Dateien ins Web zu bringen, ist BeyondPress von Extensis (www.extensis.com/beyondpress/). Auch von Quark selbst gibt es inzwischen eine XML-Extraktionslösung namens avenue.quark 1.0. Die Demo auf www.quark.com/products/avenue.quark/ zeigt die Features dieses Programms.
Praktiker sind auf alles gefasst
Derzeit steckt das Content Syndication im Web noch in den Anfängen. Sören Kress, bei der 4Content AG für die Technik verantwortlich, bringt es auf den Punkt: Leider treffen wir auf Seiten der Content-Provider selten auf die Fähigkeit, Metadaten in ausreichendem Maße zur Verfügung zu stellen, um NewsML oder PRISM zu generieren. Allerdings kann man Stand heute auch auf Seiten der Lizenznehmer in den allermeisten Fällen keine geeigneten Infrastrukturen für den Umgang mit ICE, NewsML o.ä. Standards vorfinden.
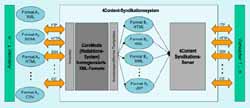
Bei den Content-Anbietern herrscht noch buntes Treiben bezüglich der Formate, in denen Inhalte vorliegen und der Protokolle, über die die Inhalte für die Syndikation übermittelt werden. Das 4Content-Syndikations-System, das auf dem Content Management System der CoreMedia AG basiert, trägt diesem Umstand flexibel Rechnung. Das Import- Framework von CoreMedia ermöglicht es, in verhältnismäßig kurzer Zeit Importer für beliebige strukturierte Formate (XML, SGML, CSV usw.) zu erstellen. Mit vertretbarem Aufwand können bei Bedarf ebenfalls Importer für Binär- Formate (Word, Excel usw.) erstellt werden.
Beim Import werden die Inhalte der unterschiedlichen Anbieter auf homogenisierte interne Datenstrukturen innerhalb von CoreMedia abgebildet. Dabei werden lediglich Strukturen und Inhalte gespeichert, Layout wird erst bei der Generierung der kundenspezifischen Formate berücksichtigt.
Intern besteht CoreMedia aus zwei Servern, die über einen Staging-Prozeß miteinander abgeglichen werden. Dadurch besteht für 4Content die Möglichkeit bei Bedarf manuelle Qualitätssicherung durchzuführen, bevor Inhalte für Lizenznehmer freigeschaltet werden. Das gesamte CoreMedia-System arbeitet event- basiert. Somit ist es möglich, automatisiert nach einem Import unverzüglich weitere Prozesse wie etwa Generierung von Ausgabeformaten für Lizenznehmer anzustoßen. Unmittelbar nach dem Import von Inhalten können für die neuen Inhalte beliebig viele unterschiedliche Ausgabeformate für die Lizenznehmer generiert werden.
Über JSP-Templates (HTML- Seiten mit eingebettetem server-seitigen Java-Code) werden die kundenspezifischen Ausgabeformate erzeugt. Auf diese Weise können nicht nur XML-, HTML- oder reine Text- Dokumente erzeugt werden, sondern auch beliebige andere Formate wie etwa PDF. Einzelne Inhalte, wie eine Nachrichtenmeldung können beliebig vielen Templates zugeordnet werden, wodurch beliebig viele unterschiedliche Layouts für ein und denselben Inhalt erzeugt werden können.
Die Schnittstelle zwischen 4Content und den Lizenznehmern wird durch den Syndikations- Server realisiert. Ebenso wie bei den Content-Anbietern müssen auch auf der Ausgabeseite bei den Lizenznehmern unterschiedlichste Protokolle (FTP, HTTP usw.) in den Variationen Push und Pull unterstützt werden. Der Syndikations-Server regelt neben der Auslieferung der lizenzierten Inhalte auch die Anbindung an das kaufmännische Backendsystem zur Unterstützung von Billing & Accounting.
Fazit
Content Syndication mit XML-Werkzeugen ist sicherlich kein ganz einfaches Metier. Das merken auch die Content Anbieter an den Preisen: der Syndikator behält in der Regel etwa 40 Prozent des Verkaufspreises für sich. Aber jeder, der mit Content sein Geld verdient, sei er nun Verleger oder Journalist, wird in Zukunft nicht um dieses Thema herumkommen.
Copyright: Roland Dreyer 2001
Web-Links:
http://www.prismstandard.org/
http://dublincore.org/
http://www.mpib-berlin.mpg.de/DOK/metatagd.htm
http://www.ietf.org/
http://www.topicmaps.org/)
http://www.idealliance.org/
Copyright: Roland Dreyer 2001
|